Ошибки импорта, ошибки расчетов.
Данные, импортированные из книги MS Excel, проверяются на наличие формальных ошибок, а также на полноту и непротиворечивость в сопоставлении с информацией, находящейся в других разделах. Сообщение о наличии ошибок в данных (если таковые есть), появляется после сессии импорта:
.png) ВАЖНО: ошибки (как экспортируемые, так и отображаемые в системе), относятся к сессии импорта или доимпорта, а не к модели данных целиком. Игнорирование ошибок в текущей сессии с последующим доимпортом части данных, не содержащих ошибок, может привести к потере информации об ошибках и иллюзии отсутствия ошибок в данных!
ВАЖНО: ошибки (как экспортируемые, так и отображаемые в системе), относятся к сессии импорта или доимпорта, а не к модели данных целиком. Игнорирование ошибок в текущей сессии с последующим доимпортом части данных, не содержащих ошибок, может привести к потере информации об ошибках и иллюзии отсутствия ошибок в данных!
Ошибки, если таковые есть, приводятся по разделам: 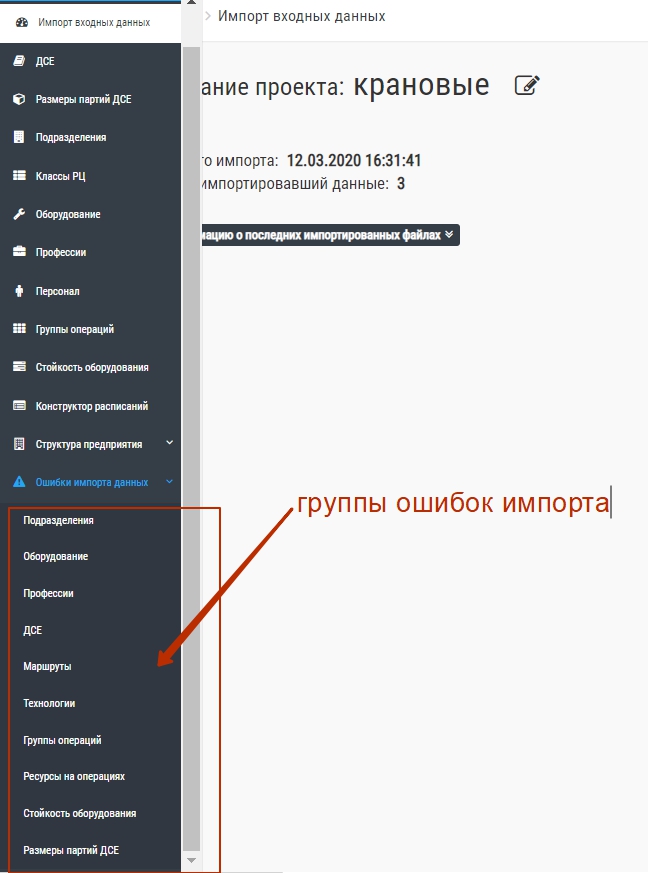
При переходе по группам ошибок отображаются ошибки (если таковые есть), с комментариями по положению источника ошибки на соответствующих листах и самой ошибке. Наведение на строку с ошибкой выведет комментарий по реакции системы на ошибку, например, как на рисунке ниже: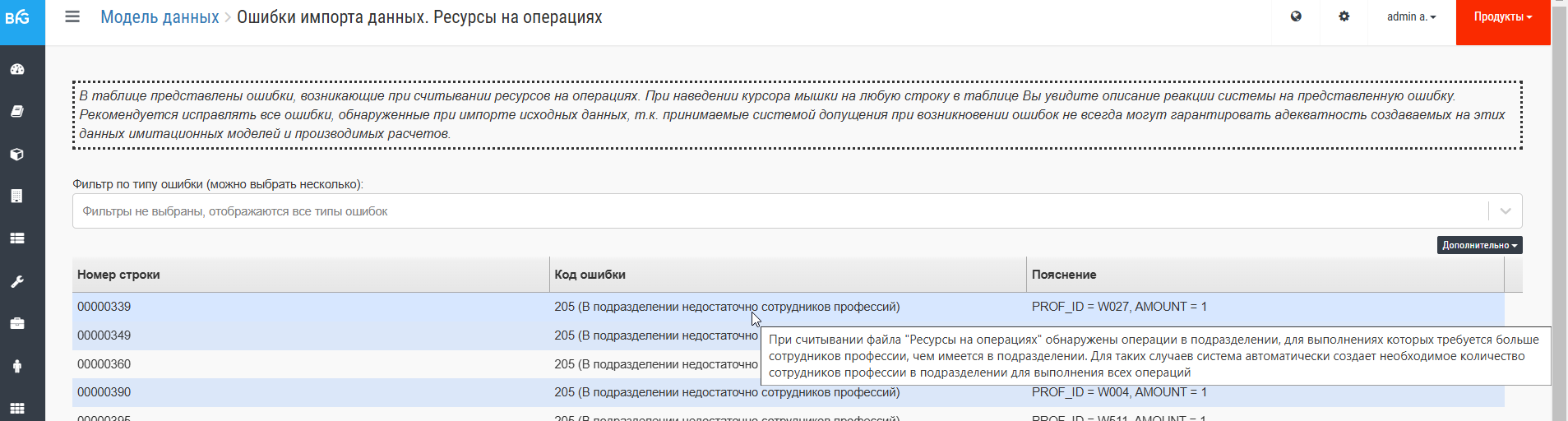 Заметим, что поиск ошибок осуществляется по чисто формальным признакам (синтаксису). В число проверяемых синтаксических ошибок входят:
Заметим, что поиск ошибок осуществляется по чисто формальным признакам (синтаксису). В число проверяемых синтаксических ошибок входят:
- недопустимые значения;
- ссылки на неизвестные сущности из других листов;
- недостаточность ресурсов для исполнения операции;
- и др.
Строка данных, содержащая ошибки, которые не могут быть обработаны, в т.ч. из-за неправильного формата, ИГНОРИРУЕТСЯ в итоговой модели данных. В т.ч. к таким ошибкам относятся:
- отрицательные значения для задания времени (технологические времена, время цикла и т.п.);
- отрицательные, нулевые или нецифровые значения в задании количеств (оборудования, вхождений в состав);
- дробные значения в задании количеств (оборудования, персонала) в подразделениях.
Система позволяет импортировать данные частями из отдельных файлов (см. здесь), при этом, если набор файлов не полный, то возможны ссылки на сущности, которые не вошли в набор файлов, импортируемых в сеансе импорта. Для предотвращения ошибок, которые могут при этом возникнуть, желательно соблюдать комплектность импорта, или, как минимум, последовательность импорта данных:
- данные о подразделениях
- данные об оборудовании в привязке к подразделениям
- данные о персонале в привязке к подазделениям
- данные о составах изделий
- данные о маршрутах для ДСЕ и изделий
- технологии для маршрутов
- ресурсы для операций технологий
- ...
Если "забыть" импортировать файл с подразделениями, то скорей всего будут ошибки, касающиеся неизвестных подразделений (если они не были импортированы ранее). Если "забыть" импортировать данные о технологии и ресурсах, то ошибок импорта не будет - т.к. все ДСЕ будут считаться не имеющими технологий - т.е. покупными.
При ошибках типа ссылки на неизвестную сущность, система взамен несуществующих создает соответствующие сущности в единственном экземпляре, и эти сущности будут соответственно отмечены.
Например, при отсутствии на листе Оборудование рабочего центра, упомянутого на листе Технология (о чем будет сообщено в соответствующем разделе):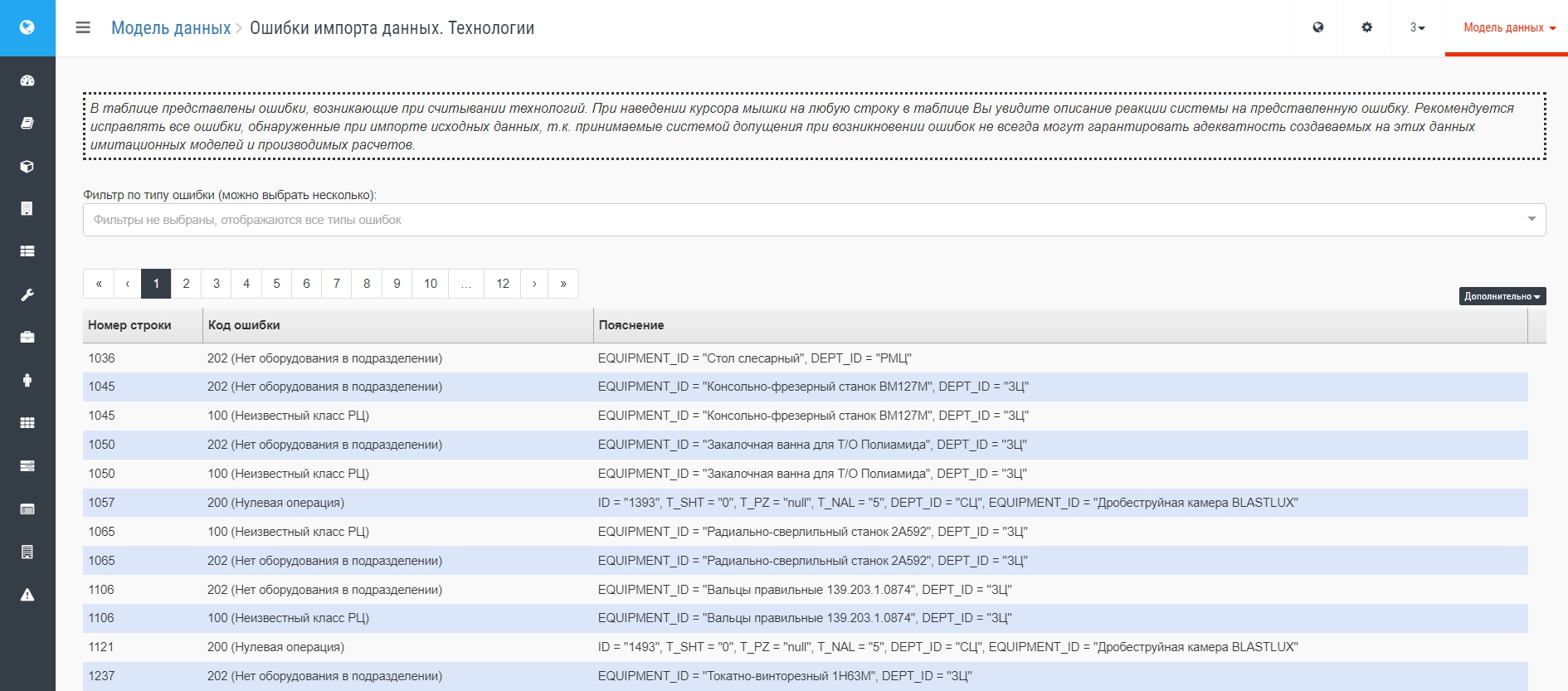 В разделе Модели данных по разделу Оборудование будут заведены помеченные префиксом ИД (искусственные данные) сущности, как на рис. ниже:
В разделе Модели данных по разделу Оборудование будут заведены помеченные префиксом ИД (искусственные данные) сущности, как на рис. ниже: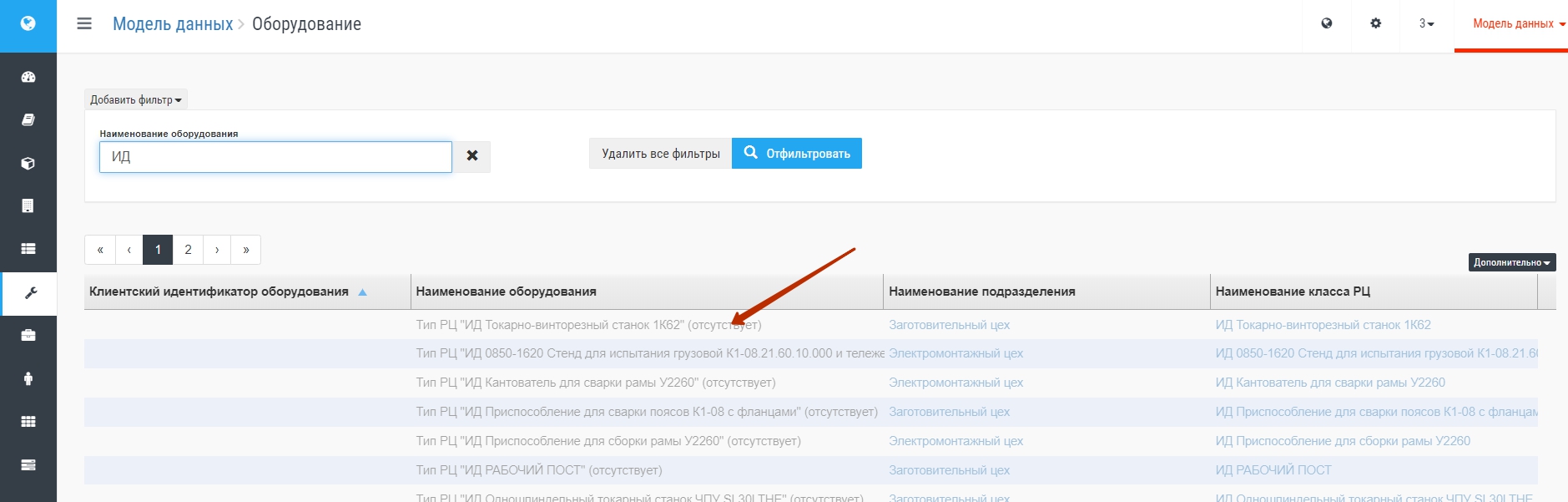 Неформальные ошибки внутри системы могут быть выявлены только в процессе моделирования (путем анализа несоответствий результатов моделирования в том или ином разделе ожиданиям или здравому смыслу) Например, если вместо имеющегося в реальности количества станков =100 поставить 1, то данный ресурс в процессе моделирования с большой вероятностью станет ограничением, что и выявится при анализе результатов.
Неформальные ошибки внутри системы могут быть выявлены только в процессе моделирования (путем анализа несоответствий результатов моделирования в том или ином разделе ожиданиям или здравому смыслу) Например, если вместо имеющегося в реальности количества станков =100 поставить 1, то данный ресурс в процессе моделирования с большой вероятностью станет ограничением, что и выявится при анализе результатов.
Есть несколько ситуаций, которые не определяются как ошибочные, но которые требуют комментария по их отработке в системе:
- допустимо использовать одинаковые EQUIPMENT_ID в таблице Оборудование для разных подразделений (одинаковые рабочие центры могут быть в разных цехах – это нормально, но это РАЗНЫЕ рабочие центры, с разным количеством станков в каждом). Однако при этом наименование NAME для EQUIPMENT_ID будет одинаковым и соответствовать первой по порядку чтения записи. При трактовке результатов могут возникнуть трудности, если не следить за тем, чтобы в этой ситуации каждому EQUIPMENT_ID соответствовало единственное значение NAME.
- аналогично, допускается использование одинаковых ID персонала для разных DEPT_ID (цехов). Но наименования NAME профессии будет то, которое прочитается первым. Во избежание путаницы, необходимо следить, чтобы каждому ID профессии соответствовало единственное наименование профессии.
- при задании количества в таблице Оборудование под AMOUNT понимается не только количество не имеющих ID станков в РЦ EQUIPMENT_ID, но все количество станков в РЦ в данном подразделении. Поэтому, если количество записей, соответствующих станкам с ID («инвентарными в цехе») будет больше, чем AMOUNT, соответствующий данному EQUIPMENT_ID, то AMOUNT проигнорируется без выдачи сообщения об ошибке. Если AMOUNT будет больше, чем количество записей с ID в той же группе EQUIPMENT_ID, то будут созданы дополнительные (не имеющие ID – клиентского идентификатора экземпляра станка.
- если в каком-либо разделе данных встретится ситуация, что имеется две синтаксически безошибочные записи, описывающие одну сущность, то вторая (и возможные следующие) запись проигнорируется. Например, из трех строк

прочитается только первая строка, а вторая и третья проигнорируются без сообщения об ошибке. Т.е. результаты будут зависеть от того, как отсортированы исходные таблицы. Это придает известную гибкость в подготовке данных, но ответственность за последствия лежит на пользователе.
Несмотря на то, что BFG-IS позволяет начать работу даже при наличии ошибок импорта - тем самым обеспечивая гибкость - настоятельно рекомендуется ошибок импорта избегать, как минимум - по каждой найденной ошибке принимать осознанные решения о необходимости корректировки.
Но даже корректно сформированные данные не могут гарантировать проведения безошибочного расчета. Связано это с комбинацией условий расчета (плана, стартового состояния производства, правил моделирования), модели данных, изменений, в сочетании с вычислительными возможностями оборудования, которые вместе не дают возможности закончить расчет. Об ошибках в ходе моделирования сигнализирует появляюшиеся сообщения, например: 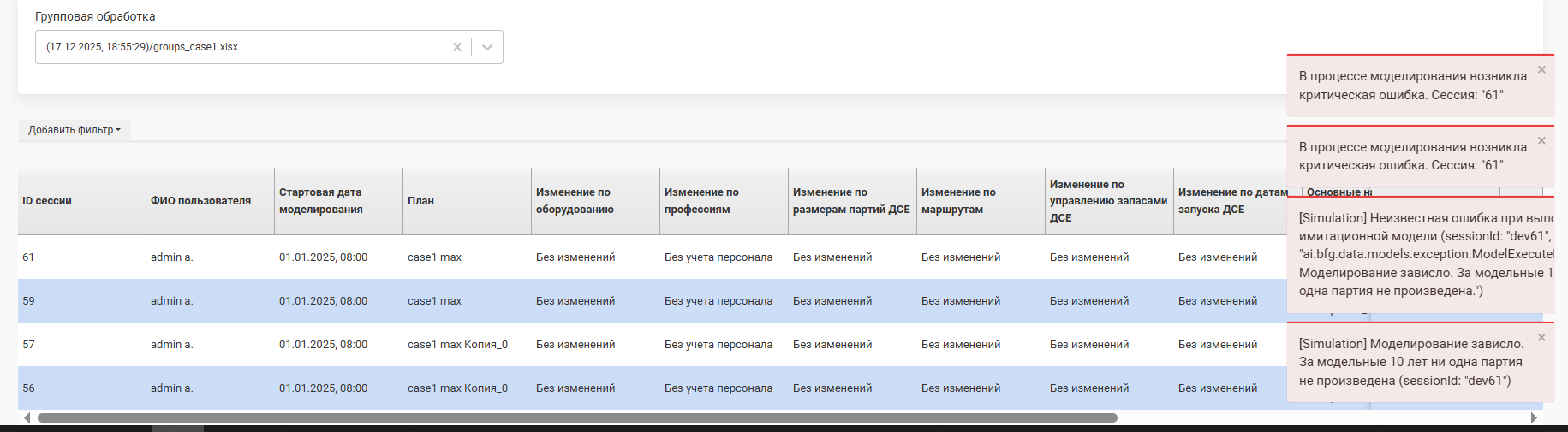 Невозможность завершить расчет может быть связана либо с исчерпанием ограничений (время, память, место для записи и т.п., см. здесь), либо с логически неразрешимыми ситуациями в ходе моделирования. Моделирование в расчетах модулей Симулятор и Планирование останавливается с сообщением об ошибке, если ни одна партия не была закончена в течение 10 лет модельного времени.
Невозможность завершить расчет может быть связана либо с исчерпанием ограничений (время, память, место для записи и т.п., см. здесь), либо с логически неразрешимыми ситуациями в ходе моделирования. Моделирование в расчетах модулей Симулятор и Планирование останавливается с сообщением об ошибке, если ни одна партия не была закончена в течение 10 лет модельного времени.